$\require{mathtools}
\newcommand{\nc}{\newcommand}
%
%%% GENERIC MATH %%%
%
% Environments
\newcommand{\al}[1]{\begin{align}#1\end{align}} % need this for \tag{} to work
\renewcommand{\r}{\mathrm} % BAD!! does cursed things with accents :((
\renewcommand{\t}{\textrm}
\newcommand{\either}[1]{\begin{cases}#1\end{cases}}
%
% Delimiters
% (I needed to create my own because the MathJax version of \DeclarePairedDelimiter doesn't have \mathopen{} and that messes up the spacing)
% .. one-part
\newcommand{\p}[1]{\mathopen{}\left( #1 \right)}
\renewcommand{\P}[1]{^{\p{#1}}}
\renewcommand{\b}[1]{\mathopen{}\left[ #1 \right]}
\newcommand{\lopen}[1]{\mathopen{}\left( #1 \right]}
\newcommand{\ropen}[1]{\mathopen{}\left[ #1 \right)}
\newcommand{\set}[1]{\mathopen{}\left\{ #1 \right\}}
\newcommand{\abs}[1]{\mathopen{}\left\lvert #1 \right\rvert}
\newcommand{\floor}[1]{\mathopen{}\left\lfloor #1 \right\rfloor}
\newcommand{\ceil}[1]{\mathopen{}\left\lceil #1 \right\rceil}
\newcommand{\round}[1]{\mathopen{}\left\lfloor #1 \right\rceil}
\newcommand{\inner}[1]{\mathopen{}\left\langle #1 \right\rangle}
\newcommand{\norm}[1]{\mathopen{}\left\lVert #1 \strut \right\rVert}
\newcommand{\frob}[1]{\norm{#1}_\mathrm{F}}
\newcommand{\mix}[1]{\mathopen{}\left\lfloor #1 \right\rceil}
%% .. two-part
\newcommand{\inco}[2]{#1 \mathop{}\middle|\mathop{} #2}
\newcommand{\co}[2]{ {\left.\inco{#1}{#2}\right.}}
\newcommand{\cond}{\co} % deprecated
\newcommand{\pco}[2]{\p{\inco{#1}{#2}}}
\newcommand{\bco}[2]{\b{\inco{#1}{#2}}}
\newcommand{\setco}[2]{\set{\inco{#1}{#2}}}
\newcommand{\at}[2]{ {\left.#1\strut\right|_{#2}}}
\newcommand{\pat}[2]{\p{\at{#1}{#2}}}
\newcommand{\bat}[2]{\b{\at{#1}{#2}}}
\newcommand{\para}[2]{#1\strut \mathop{}\middle\|\mathop{} #2}
\newcommand{\ppa}[2]{\p{\para{#1}{#2}}}
\newcommand{\pff}[2]{\p{\ff{#1}{#2}}}
\newcommand{\bff}[2]{\b{\ff{#1}{#2}}}
\newcommand{\bffco}[4]{\bff{\cond{#1}{#2}}{\cond{#3}{#4}}}
\newcommand{\sm}[1]{\p{\begin{smallmatrix}#1\end{smallmatrix}}}
%
% Greek
\newcommand{\eps}{\epsilon}
\newcommand{\veps}{\varepsilon}
\newcommand{\vpi}{\varpi}
% the following cause issues with real LaTeX tho :/ maybe consider naming it \fhi instead?
\let\fi\phi % because it looks like an f
\let\phi\varphi % because it looks like a p
\renewcommand{\th}{\theta}
\newcommand{\Th}{\Theta}
\newcommand{\om}{\omega}
\newcommand{\Om}{\Omega}
%
% Miscellaneous
\newcommand{\LHS}{\mathrm{LHS}}
\newcommand{\RHS}{\mathrm{RHS}}
\DeclareMathOperator{\cst}{const}
% .. operators
\DeclareMathOperator{\poly}{poly}
\DeclareMathOperator{\polylog}{polylog}
\DeclareMathOperator{\quasipoly}{quasipoly}
\DeclareMathOperator{\negl}{negl}
\DeclareMathOperator*{\argmin}{arg\thinspace min}
\DeclareMathOperator*{\argmax}{arg\thinspace max}
\DeclareMathOperator{\diag}{diag}
% .. functions
\DeclareMathOperator{\id}{id}
\DeclareMathOperator{\sign}{sign}
\DeclareMathOperator{\step}{step}
\DeclareMathOperator{\err}{err}
\DeclareMathOperator{\ReLU}{ReLU}
\DeclareMathOperator{\softmax}{softmax}
% .. analysis
\let\d\undefined
\newcommand{\d}{\operatorname{d}\mathopen{}}
\newcommand{\dd}[1]{\operatorname{d}^{#1}\mathopen{}}
\newcommand{\df}[2]{ {\f{\d #1}{\d #2}}}
\newcommand{\ds}[2]{ {\sl{\d #1}{\d #2}}}
\newcommand{\ddf}[3]{ {\f{\dd{#1} #2}{\p{\d #3}^{#1}}}}
\newcommand{\dds}[3]{ {\sl{\dd{#1} #2}{\p{\d #3}^{#1}}}}
\renewcommand{\part}{\partial}
\newcommand{\ppart}[1]{\part^{#1}}
\newcommand{\partf}[2]{\f{\part #1}{\part #2}}
\newcommand{\parts}[2]{\sl{\part #1}{\part #2}}
\newcommand{\ppartf}[3]{ {\f{\ppart{#1} #2}{\p{\part #3}^{#1}}}}
\newcommand{\pparts}[3]{ {\sl{\ppart{#1} #2}{\p{\part #3}^{#1}}}}
\newcommand{\grad}[1]{\mathop{\nabla\!_{#1}}}
% .. sets
\newcommand{\es}{\emptyset}
\newcommand{\N}{\mathbb{N}}
\newcommand{\Z}{\mathbb{Z}}
\newcommand{\R}{\mathbb{R}}
\newcommand{\Rge}{\R_{\ge 0}}
\newcommand{\Rgt}{\R_{> 0}}
\newcommand{\C}{\mathbb{C}}
\newcommand{\F}{\mathbb{F}}
\newcommand{\zo}{\set{0,1}}
\newcommand{\pmo}{\set{\pm 1}}
\newcommand{\zpmo}{\set{0,\pm 1}}
% .... set operations
\newcommand{\sse}{\subseteq}
\newcommand{\out}{\not\in}
\newcommand{\minus}{\setminus}
\newcommand{\inc}[1]{\union \set{#1}} % "including"
\newcommand{\exc}[1]{\setminus \set{#1}} % "except"
% .. over and under
\renewcommand{\ss}[1]{_{\substack{#1}}}
\newcommand{\OB}{\overbrace}
\newcommand{\ob}[2]{\OB{#1}^\t{#2}}
\newcommand{\UB}{\underbrace}
\newcommand{\ub}[2]{\UB{#1}_\t{#2}}
\newcommand{\ol}{\overline}
\newcommand{\tld}{\widetilde} % deprecated
\renewcommand{\~}{\widetilde}
\newcommand{\HAT}{\widehat} % deprecated
\renewcommand{\^}{\widehat}
\newcommand{\rt}[1]{ {\sqrt{#1}}}
\newcommand{\for}[2]{_{#1=1}^{#2}}
\newcommand{\sfor}{\sum\for}
\newcommand{\pfor}{\prod\for}
% .... two-part
\newcommand{\f}{\frac}
\renewcommand{\sl}[2]{#1 /\mathopen{}#2}
\newcommand{\ff}[2]{\mathchoice{\begin{smallmatrix}\displaystyle\vphantom{\p{#1}}#1\\[-0.05em]\hline\\[-0.05em]\hline\displaystyle\vphantom{\p{#2}}#2\end{smallmatrix}}{\begin{smallmatrix}\vphantom{\p{#1}}#1\\[-0.1em]\hline\\[-0.1em]\hline\vphantom{\p{#2}}#2\end{smallmatrix}}{\begin{smallmatrix}\vphantom{\p{#1}}#1\\[-0.1em]\hline\\[-0.1em]\hline\vphantom{\p{#2}}#2\end{smallmatrix}}{\begin{smallmatrix}\vphantom{\p{#1}}#1\\[-0.1em]\hline\\[-0.1em]\hline\vphantom{\p{#2}}#2\end{smallmatrix}}}
% .. arrows
\newcommand{\from}{\leftarrow}
\DeclareMathOperator*{\<}{\!\;\longleftarrow\;\!}
\let\>\undefined
\DeclareMathOperator*{\>}{\!\;\longrightarrow\;\!}
\let\-\undefined
\DeclareMathOperator*{\-}{\!\;\longleftrightarrow\;\!}
\newcommand{\so}{\implies}
% .. operators and relations
\renewcommand{\*}{\cdot}
\newcommand{\x}{\times}
\newcommand{\ox}{\otimes}
\newcommand{\OX}[1]{^{\ox #1}}
\newcommand{\sr}{\stackrel}
\newcommand{\ce}{\coloneqq}
\newcommand{\ec}{\eqqcolon}
\newcommand{\ap}{\approx}
\newcommand{\ls}{\lesssim}
\newcommand{\gs}{\gtrsim}
% .. punctuation and spacing
\renewcommand{\.}[1]{#1\dots#1}
\newcommand{\ts}{\thinspace}
\newcommand{\q}{\quad}
\newcommand{\qq}{\qquad}
%
%
%%% SPECIALIZED MATH %%%
%
% Logic and bit operations
\newcommand{\fa}{\forall}
\newcommand{\ex}{\exists}
\renewcommand{\and}{\wedge}
\newcommand{\AND}{\bigwedge}
\renewcommand{\or}{\vee}
\newcommand{\OR}{\bigvee}
\newcommand{\xor}{\oplus}
\newcommand{\XOR}{\bigoplus}
\newcommand{\union}{\cup}
\newcommand{\dunion}{\sqcup}
\newcommand{\inter}{\cap}
\newcommand{\UNION}{\bigcup}
\newcommand{\DUNION}{\bigsqcup}
\newcommand{\INTER}{\bigcap}
\newcommand{\comp}{\overline}
\newcommand{\true}{\r{true}}
\newcommand{\false}{\r{false}}
\newcommand{\tf}{\set{\true,\false}}
\DeclareMathOperator{\One}{\mathbb{1}}
\DeclareMathOperator{\1}{\mathbb{1}} % use \mathbbm instead if using real LaTeX
\DeclareMathOperator{\LSB}{LSB}
%
% Linear algebra
\newcommand{\spn}{\mathrm{span}} % do NOT use \span because it causes misery with amsmath
\DeclareMathOperator{\rank}{rank}
\DeclareMathOperator{\proj}{proj}
\DeclareMathOperator{\dom}{dom}
\DeclareMathOperator{\Img}{Im}
\DeclareMathOperator{\tr}{tr}
\DeclareMathOperator{\perm}{perm}
\DeclareMathOperator{\haf}{haf}
\newcommand{\transp}{\mathsf{T}}
\newcommand{\T}{^\transp}
\newcommand{\par}{\parallel}
% .. named tensors
\newcommand{\namedtensorstrut}{\vphantom{fg}} % milder than \mathstrut
\newcommand{\name}[1]{\mathsf{\namedtensorstrut #1}}
\newcommand{\nbin}[2]{\mathbin{\underset{\substack{#1}}{\namedtensorstrut #2}}}
\newcommand{\ndot}[1]{\nbin{#1}{\odot}}
\newcommand{\ncat}[1]{\nbin{#1}{\oplus}}
\newcommand{\nsum}[1]{\sum\limits_{\substack{#1}}}
\newcommand{\nfun}[2]{\mathop{\underset{\substack{#1}}{\namedtensorstrut\mathrm{#2}}}}
\newcommand{\ndef}[2]{\newcommand{#1}{\name{#2}}}
\newcommand{\nt}[1]{^{\transp(#1)}}
%
% Probability
\newcommand{\tri}{\triangle}
\newcommand{\Normal}{\mathcal{N}}
\newcommand{\Exp}{\mathcal{Exp}}
% .. operators
\DeclareMathOperator{\supp}{supp}
\let\Pr\undefined
\DeclareMathOperator*{\Pr}{Pr}
\DeclareMathOperator*{\G}{\mathbb{G}}
\DeclareMathOperator*{\Odds}{Od}
\DeclareMathOperator*{\E}{E}
\DeclareMathOperator*{\Var}{Var}
\DeclareMathOperator*{\Cov}{Cov}
\DeclareMathOperator*{\K}{K}
\DeclareMathOperator*{\corr}{corr}
\DeclareMathOperator*{\median}{median}
\DeclareMathOperator*{\maj}{maj}
% ... information theory
\let\H\undefined
\DeclareMathOperator*{\H}{H}
\DeclareMathOperator*{\I}{I}
\DeclareMathOperator*{\D}{D}
\DeclareMathOperator*{\KL}{KL}
% .. other divergences
\newcommand{\dTV}{d_{\mathrm{TV}}}
\newcommand{\dHel}{d_{\mathrm{Hel}}}
\newcommand{\dJS}{d_{\mathrm{JS}}}
%
% Polynomials
\DeclareMathOperator{\He}{He}
\DeclareMathOperator{\coeff}{coeff}
%
%%% SPECIALIZED COMPUTER SCIENCE %%%
%
% Complexity classes
% .. keywords
\newcommand{\coclass}{\mathsf{co}}
\newcommand{\Prom}{\mathsf{Promise}}
% .. classical
\newcommand{\PTIME}{\mathsf{P}}
\newcommand{\NP}{\mathsf{NP}}
\newcommand{\coNP}{\coclass\NP}
\newcommand{\PH}{\mathsf{PH}}
\newcommand{\PSPACE}{\mathsf{PSPACE}}
\renewcommand{\L}{\mathsf{L}}
\newcommand{\EXP}{\mathsf{EXP}}
\newcommand{\NEXP}{\mathsf{NEXP}}
% .. probabilistic
\newcommand{\formost}{\mathsf{Я}}
\newcommand{\RP}{\mathsf{RP}}
\newcommand{\BPP}{\mathsf{BPP}}
\newcommand{\ZPP}{\mathsf{ZPP}}
\newcommand{\MA}{\mathsf{MA}}
\newcommand{\AM}{\mathsf{AM}}
\newcommand{\IP}{\mathsf{IP}}
\newcommand{\RL}{\mathsf{RL}}
% .. circuits
\newcommand{\NC}{\mathsf{NC}}
\newcommand{\AC}{\mathsf{AC}}
\newcommand{\ACC}{\mathsf{ACC}}
\newcommand{\ThrC}{\mathsf{TC}}
\newcommand{\Ppoly}{\mathsf{P}/\poly}
\newcommand{\Lpoly}{\mathsf{L}/\poly}
% .. resources
\newcommand{\TIME}{\mathsf{TIME}}
\newcommand{\NTIME}{\mathsf{NTIME}}
\newcommand{\SPACE}{\mathsf{SPACE}}
\newcommand{\TISP}{\mathsf{TISP}}
\newcommand{\SIZE}{\mathsf{SIZE}}
% .. custom
\newcommand{\NCP}{\mathsf{NCP}}
%
% Boolean analysis
\newcommand{\harpoon}{\!\upharpoonright\!}
\newcommand{\rr}[2]{#1\harpoon_{#2}}
\newcommand{\Fou}[1]{\widehat{#1}}
\DeclareMathOperator{\Ind}{\mathrm{Ind}}
\DeclareMathOperator{\Inf}{\mathrm{Inf}}
\newcommand{\Der}[1]{\operatorname{D}_{#1}\mathopen{}}
% \newcommand{\Exp}[1]{\operatorname{E}_{#1}\mathopen{}}
\DeclareMathOperator{\Stab}{\mathrm{Stab}}
\DeclareMathOperator{\Tau}{T}
\DeclareMathOperator{\sens}{\mathrm{s}}
\DeclareMathOperator{\bsens}{\mathrm{bs}}
\DeclareMathOperator{\fbsens}{\mathrm{fbs}}
\DeclareMathOperator{\Cert}{\mathrm{C}}
\DeclareMathOperator{\DT}{\mathrm{DT}}
\DeclareMathOperator{\CDT}{\mathrm{CDT}} % canonical
\DeclareMathOperator{\ECDT}{\mathrm{ECDT}}
\DeclareMathOperator{\CDTv}{\mathrm{CDT_{vars}}}
\DeclareMathOperator{\ECDTv}{\mathrm{ECDT_{vars}}}
\DeclareMathOperator{\CDTt}{\mathrm{CDT_{terms}}}
\DeclareMathOperator{\ECDTt}{\mathrm{ECDT_{terms}}}
\DeclareMathOperator{\CDTw}{\mathrm{CDT_{weighted}}}
\DeclareMathOperator{\ECDTw}{\mathrm{ECDT_{weighted}}}
\DeclareMathOperator{\AvgDT}{\mathrm{AvgDT}}
\DeclareMathOperator{\PDT}{\mathrm{PDT}} % partial decision tree
\DeclareMathOperator{\DTsize}{\mathrm{DT_{size}}}
\DeclareMathOperator{\W}{\mathbf{W}}
% .. functions (small caps sadly doesn't work)
\DeclareMathOperator{\Par}{\mathrm{Par}}
\DeclareMathOperator{\Maj}{\mathrm{Maj}}
\DeclareMathOperator{\HW}{\mathrm{HW}}
\DeclareMathOperator{\Thr}{\mathrm{Thr}}
\DeclareMathOperator{\Tribes}{\mathrm{Tribes}}
\DeclareMathOperator{\RotTribes}{\mathrm{RotTribes}}
\DeclareMathOperator{\CycleRun}{\mathrm{CycleRun}}
\DeclareMathOperator{\SAT}{\mathrm{SAT}}
\DeclareMathOperator{\UniqueSAT}{\mathrm{UniqueSAT}}
%
% Dynamic optimality
\newcommand{\OPT}{\mathsf{OPT}}
\newcommand{\Alt}{\mathsf{Alt}}
\newcommand{\Funnel}{\mathsf{Funnel}}
%
% Alignment
\DeclareMathOperator{\Amp}{\mathrm{Amp}}
%
%%% TYPESETTING %%%
%
% In "text"
\newcommand{\heart}{\heartsuit}
\newcommand{\nth}{^\t{th}}
\newcommand{\degree}{^\circ}
\newcommand{\qu}[1]{\text{``}#1\text{''}}
% remove these last two if using real LaTeX
\newcommand{\qed}{\blacksquare}
\newcommand{\qedhere}{\tag*{$\blacksquare$}}
%
% Fonts
% .. bold
\newcommand{\BA}{\boldsymbol{A}}
\newcommand{\BB}{\boldsymbol{B}}
\newcommand{\BC}{\boldsymbol{C}}
\newcommand{\BD}{\boldsymbol{D}}
\newcommand{\BE}{\boldsymbol{E}}
\newcommand{\BF}{\boldsymbol{F}}
\newcommand{\BG}{\boldsymbol{G}}
\newcommand{\BH}{\boldsymbol{H}}
\newcommand{\BI}{\boldsymbol{I}}
\newcommand{\BJ}{\boldsymbol{J}}
\newcommand{\BK}{\boldsymbol{K}}
\newcommand{\BL}{\boldsymbol{L}}
\newcommand{\BM}{\boldsymbol{M}}
\newcommand{\BN}{\boldsymbol{N}}
\newcommand{\BO}{\boldsymbol{O}}
\newcommand{\BP}{\boldsymbol{P}}
\newcommand{\BQ}{\boldsymbol{Q}}
\newcommand{\BR}{\boldsymbol{R}}
\newcommand{\BS}{\boldsymbol{S}}
\newcommand{\BT}{\boldsymbol{T}}
\newcommand{\BU}{\boldsymbol{U}}
\newcommand{\BV}{\boldsymbol{V}}
\newcommand{\BW}{\boldsymbol{W}}
\newcommand{\BX}{\boldsymbol{X}}
\newcommand{\BY}{\boldsymbol{Y}}
\newcommand{\BZ}{\boldsymbol{Z}}
\newcommand{\Ba}{\boldsymbol{a}}
\newcommand{\Bb}{\boldsymbol{b}}
\newcommand{\Bc}{\boldsymbol{c}}
\newcommand{\Bd}{\boldsymbol{d}}
\newcommand{\Be}{\boldsymbol{e}}
\newcommand{\Bf}{\boldsymbol{f}}
\newcommand{\Bg}{\boldsymbol{g}}
\newcommand{\Bh}{\boldsymbol{h}}
\newcommand{\Bi}{\boldsymbol{i}}
\newcommand{\Bj}{\boldsymbol{j}}
\newcommand{\Bk}{\boldsymbol{k}}
\newcommand{\Bl}{\boldsymbol{l}}
\newcommand{\Bm}{\boldsymbol{m}}
\newcommand{\Bn}{\boldsymbol{n}}
\newcommand{\Bo}{\boldsymbol{o}}
\newcommand{\Bp}{\boldsymbol{p}}
\newcommand{\Bq}{\boldsymbol{q}}
\newcommand{\Br}{\boldsymbol{r}}
\newcommand{\Bs}{\boldsymbol{s}}
\newcommand{\Bt}{\boldsymbol{t}}
\newcommand{\Bu}{\boldsymbol{u}}
\newcommand{\Bv}{\boldsymbol{v}}
\newcommand{\Bw}{\boldsymbol{w}}
\newcommand{\Bx}{\boldsymbol{x}}
\newcommand{\By}{\boldsymbol{y}}
\newcommand{\Bz}{\boldsymbol{z}}
\newcommand{\Balpha}{\boldsymbol{\alpha}}
\newcommand{\Bbeta}{\boldsymbol{\beta}}
\newcommand{\Bgamma}{\boldsymbol{\gamma}}
\newcommand{\Bdelta}{\boldsymbol{\delta}}
\newcommand{\Beps}{\boldsymbol{\eps}}
\newcommand{\Bveps}{\boldsymbol{\veps}}
\newcommand{\Bzeta}{\boldsymbol{\zeta}}
\newcommand{\Beta}{\boldsymbol{\eta}}
\newcommand{\Btheta}{\boldsymbol{\theta}}
\newcommand{\Bth}{\boldsymbol{\th}}
\newcommand{\Biota}{\boldsymbol{\iota}}
\newcommand{\Bkappa}{\boldsymbol{\kappa}}
\newcommand{\Blambda}{\boldsymbol{\lambda}}
\newcommand{\Bmu}{\boldsymbol{\mu}}
\newcommand{\Bnu}{\boldsymbol{\nu}}
\newcommand{\Bxi}{\boldsymbol{\xi}}
\newcommand{\Bpi}{\boldsymbol{\pi}}
\newcommand{\Bvpi}{\boldsymbol{\vpi}}
\newcommand{\Brho}{\boldsymbol{\rho}}
\newcommand{\Bsigma}{\boldsymbol{\sigma}}
\newcommand{\Btau}{\boldsymbol{\tau}}
\newcommand{\Bupsilon}{\boldsymbol{\upsilon}}
\newcommand{\Bphi}{\boldsymbol{\phi}}
\newcommand{\Bfi}{\boldsymbol{\fi}}
\newcommand{\Bchi}{\boldsymbol{\chi}}
\newcommand{\Bpsi}{\boldsymbol{\psi}}
\newcommand{\Bom}{\boldsymbol{\om}}
% .. calligraphic
\newcommand{\CA}{\mathcal{A}}
\newcommand{\CB}{\mathcal{B}}
\newcommand{\CC}{\mathcal{C}}
\newcommand{\CD}{\mathcal{D}}
\newcommand{\CE}{\mathcal{E}}
\newcommand{\CF}{\mathcal{F}}
\newcommand{\CG}{\mathcal{G}}
\newcommand{\CH}{\mathcal{H}}
\newcommand{\CI}{\mathcal{I}}
\newcommand{\CJ}{\mathcal{J}}
\newcommand{\CK}{\mathcal{K}}
\newcommand{\CL}{\mathcal{L}}
\newcommand{\CM}{\mathcal{M}}
\newcommand{\CN}{\mathcal{N}}
\newcommand{\CO}{\mathcal{O}}
\newcommand{\CP}{\mathcal{P}}
\newcommand{\CQ}{\mathcal{Q}}
\newcommand{\CR}{\mathcal{R}}
\newcommand{\CS}{\mathcal{S}}
\newcommand{\CT}{\mathcal{T}}
\newcommand{\CU}{\mathcal{U}}
\newcommand{\CV}{\mathcal{V}}
\newcommand{\CW}{\mathcal{W}}
\newcommand{\CX}{\mathcal{X}}
\newcommand{\CY}{\mathcal{Y}}
\newcommand{\CZ}{\mathcal{Z}}
% .. typewriter
\newcommand{\TA}{\mathtt{A}}
\newcommand{\TB}{\mathtt{B}}
\newcommand{\TC}{\mathtt{C}}
\newcommand{\TD}{\mathtt{D}}
\newcommand{\TE}{\mathtt{E}}
\newcommand{\TF}{\mathtt{F}}
\newcommand{\TG}{\mathtt{G}}
\renewcommand{\TH}{\mathtt{H}}
\newcommand{\TI}{\mathtt{I}}
\newcommand{\TJ}{\mathtt{J}}
\newcommand{\TK}{\mathtt{K}}
\newcommand{\TL}{\mathtt{L}}
\newcommand{\TM}{\mathtt{M}}
\newcommand{\TN}{\mathtt{N}}
\newcommand{\TO}{\mathtt{O}}
\newcommand{\TP}{\mathtt{P}}
\newcommand{\TQ}{\mathtt{Q}}
\newcommand{\TR}{\mathtt{R}}
\newcommand{\TS}{\mathtt{S}}
\newcommand{\TT}{\mathtt{T}}
\newcommand{\TU}{\mathtt{U}}
\newcommand{\TV}{\mathtt{V}}
\newcommand{\TW}{\mathtt{W}}
\newcommand{\TX}{\mathtt{X}}
\newcommand{\TY}{\mathtt{Y}}
\newcommand{\TZ}{\mathtt{Z}}
%
% LEVELS OF CLOSENESS (basically deprecated)
\newcommand{\scirc}[1]{\sr{\circ}{#1}}
\newcommand{\sdot}[1]{\sr{.}{#1}}
\newcommand{\slog}[1]{\sr{\log}{#1}}
\newcommand{\createClosenessLevels}[7]{
\newcommand{#2}{\mathrel{(#1)}}
\newcommand{#3}{\mathrel{#1}}
\newcommand{#4}{\mathrel{#1\!\!#1}}
\newcommand{#5}{\mathrel{#1\!\!#1\!\!#1}}
\newcommand{#6}{\mathrel{(\sdot{#1})}}
\newcommand{#7}{\mathrel{(\slog{#1})}}
}
\let\lt\undefined
\let\gt\undefined
% .. vanilla versions (is it within a constant?)
\newcommand{\ez}{\scirc=}
\newcommand{\eq}{\simeq}
\newcommand{\eqq}{\mathrel{\eq\!\!\eq}}
\newcommand{\eqqq}{\mathrel{\eq\!\!\eq\!\!\eq}}
\newcommand{\lez}{\scirc\le}
\renewcommand{\lq}{\preceq}
\newcommand{\lqq}{\mathrel{\lq\!\!\lq}}
\newcommand{\lqqq}{\mathrel{\lq\!\!\lq\!\!\lq}}
\newcommand{\gez}{\scirc\ge}
\newcommand{\gq}{\succeq}
\newcommand{\gqq}{\mathrel{\gq\!\!\gq}}
\newcommand{\gqqq}{\mathrel{\gq\!\!\gq\!\!\gq}}
\newcommand{\lz}{\scirc<}
\newcommand{\lt}{\prec}
\newcommand{\ltt}{\mathrel{\lt\!\!\lt}}
\newcommand{\lttt}{\mathrel{\lt\!\!\lt\!\!\lt}}
\newcommand{\gz}{\scirc>}
\newcommand{\gt}{\succ}
\newcommand{\gtt}{\mathrel{\gt\!\!\gt}}
\newcommand{\gttt}{\mathrel{\gt\!\!\gt\!\!\gt}}
% .. dotted versions (is it equal in the limit?)
\newcommand{\ed}{\sdot=}
\newcommand{\eqd}{\sdot\eq}
\newcommand{\eqqd}{\sdot\eqq}
\newcommand{\eqqqd}{\sdot\eqqq}
\newcommand{\led}{\sdot\le}
\newcommand{\lqd}{\sdot\lq}
\newcommand{\lqqd}{\sdot\lqq}
\newcommand{\lqqqd}{\sdot\lqqq}
\newcommand{\ged}{\sdot\ge}
\newcommand{\gqd}{\sdot\gq}
\newcommand{\gqqd}{\sdot\gqq}
\newcommand{\gqqqd}{\sdot\gqqq}
\newcommand{\ld}{\sdot<}
\newcommand{\ltd}{\sdot\lt}
\newcommand{\lttd}{\sdot\ltt}
\newcommand{\ltttd}{\sdot\lttt}
\newcommand{\gd}{\sdot>}
\newcommand{\gtd}{\sdot\gt}
\newcommand{\gttd}{\sdot\gtt}
\newcommand{\gtttd}{\sdot\gttt}
% .. log versions (is it equal up to log?)
\newcommand{\elog}{\slog=}
\newcommand{\eqlog}{\slog\eq}
\newcommand{\eqqlog}{\slog\eqq}
\newcommand{\eqqqlog}{\slog\eqqq}
\newcommand{\lelog}{\slog\le}
\newcommand{\lqlog}{\slog\lq}
\newcommand{\lqqlog}{\slog\lqq}
\newcommand{\lqqqlog}{\slog\lqqq}
\newcommand{\gelog}{\slog\ge}
\newcommand{\gqlog}{\slog\gq}
\newcommand{\gqqlog}{\slog\gqq}
\newcommand{\gqqqlog}{\slog\gqqq}
\newcommand{\llog}{\slog<}
\newcommand{\ltlog}{\slog\lt}
\newcommand{\lttlog}{\slog\ltt}
\newcommand{\ltttlog}{\slog\lttt}
\newcommand{\glog}{\slog>}
\newcommand{\gtlog}{\slog\gt}
\newcommand{\gttlog}{\slog\gtt}
\newcommand{\gtttlog}{\slog\gttt}$
Adapted from a workshop talk by C Ramya at FSTTCS 2020.
The rigidity of a matrix is a notion of how “robustly high degree” it is. Formally, the $r$-rigidity of a matrix $M \in \F^{n \times n}$, denoted $R_r(M)$, is how many entries you need to modify in $M$ in order to lower the rank to $\leq r$.
What’s the most rigid you could be?
Here’s a generic strategy you could use to make $M$ have rank $\leq r$:
- leave the first few rows as is until the rank reaches $r$;
- for every subsequent row, shoehorn it into it the span of the previous rows.
Intuitively, to make a row fit into a space of dimension $r$, you need to “get rid of $n-r$ of the $n$ degrees of freedom”, so it seems like you should be able to do it by changing $n-r$ coordinates. But an arbitrary set $n-r$ of coordinates won’t always do: for example, no value of $x$ can make this matrix rank $2$:
\[
\begin{pmatrix}
1 & 0 & 0\\
0 & 1 & 0\\
x & 0 & 1
\end{pmatrix}
\]
But you can indeed shoehorn any row $u \in \F^n$ into a space $V$ of dimension $r$ by modifying at most $n-r$ coordinates as long as you get to choose which ones:
- identify a subset $S$ of $r$ coordinates on which $V$ has full rank;
- because $V$ has full rank on $S$, there must be some $v \in V$ that matches $u$ on $S$;
- change $u$ to $v$.
Up to a permutation of the columns, this is what happens:
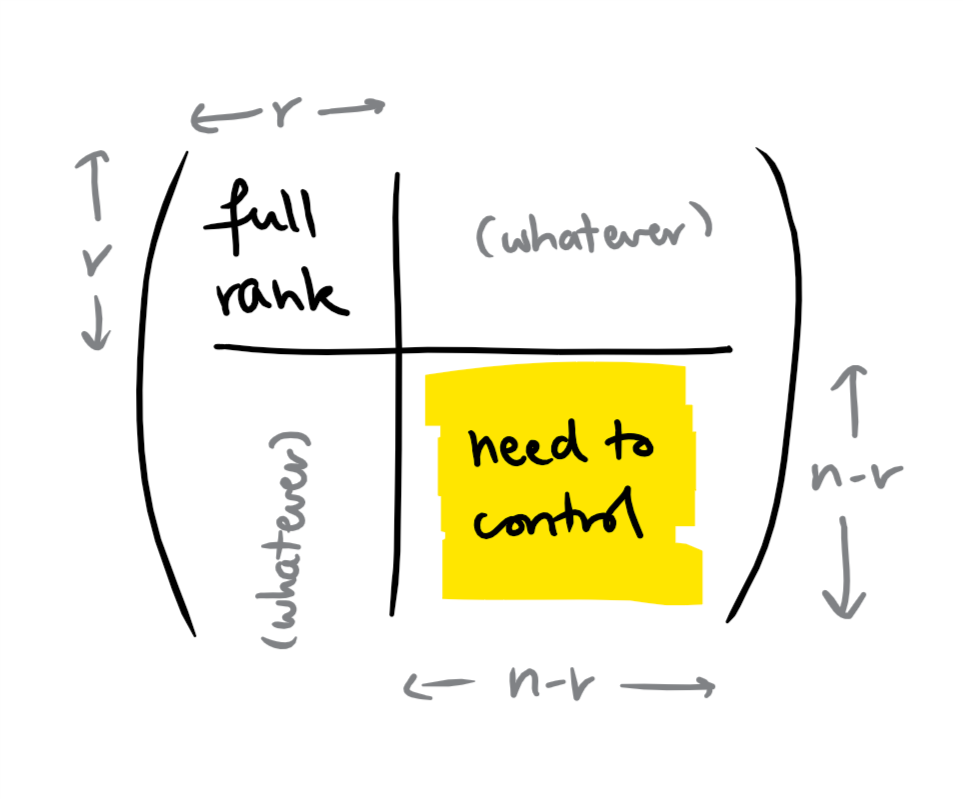
Therefore, we only need to change $n-r$ coordinates per row, and we need to do this only for the $n-r$ last rows in the worst case, so $R_r(M) \leq (n-r)^2$.
Random matrices are rigid
It turns out this $(n-r)^2$ is tight: when the field $\F$ is big enough, a random matrix has rigidity $(n-r)^2$ with high probability.
By a direct probability computation
This is because the shoehorning trick itself is tight. Indeed, for any space $V \sse \F^n$ and any set $S$ of $> \dim(V)$ coordinates, a random vector over $\F^S$ will lie outside of $V_S$ except w.p. $1/|\F|$. This means that a random row $u \in \F^n$ is overwhelmingly likely to increase the dimension of $V$, even if $u$ is later modified adversarially outside of $S$.
Therefore, by a union bound, unless we’re modifying at least $n-r$ coordinates in a row, the row will be overwhelmingly likely to increase the rank (unless the rank is already $>r$). Therefore, to make sure the rank is $\leq r$, we need to modify at least $n-r$ coordinates in at least $n-r$ of the rows.
By a counting argument
More formally, matrices such that $R_r(M) \leq s$ can be written as the sum of an $s$-sparse matrix and a matrix of rank $\leq r$, so there can only be at most
\[\underbrace{\binom{n^2}{s}|\F|^s}_\text{$s$-sparse matrices} \times \underbrace{\binom{n}{r}^2 |\F|^{n^2-(n-r)^2}}_\text{matrices of rank $\leq r$}\]
of them, while there are exactly $|\F|^{n^2}$ matrices total. So, as long as
\[
\begin{align*}
\binom{n^2}{s}|\F|^s \times \binom{n}{r}^2 |\F|^{n^2-(n-r)^2} &\ll |\F|^{n^2}\\
\Leftrightarrow \binom{n^2}{s}|\F|^s &\ll \frac{|\F|^{(n-r)^2}}{\binom{n}{r}^2},
\end{align*}
\]
then most matrices have $R_r(M) > s$.
TODO: make note proving that bound on # of rank-k matrices
If $\F$ is big enough to overwhelm the binomials (say, if $|\F| \geq 2^{n^3}$), then we can set $s = (n-r)^2-1$, which shows that most matrices have rigidity at least $(n-r)^2$ as we showed earlier.
But even in the worst case, when $|\F| = 2$, we can still get good bounds. Taking the log and approximating the binomials, the inequality becomes
\[2s\log n + s < (n-r)^2 - 2r \log n,\]
After dropping negligible terms, we’re left with $2s \log n < (n-r)^2$, which means most matrices have rigidity at least $\Omega\p{(n-r)^2/\log n}$. This only a log factor away from the upper bound.
Explicit rigid matrices
It would be great to construct explicit matrices whose rigidity matches that of random matrices. In fact, if one could find matrices such that $R_{\delta n}(M) \geq n^{1+\eps}$ for some constants $\delta,\eps>0$, this would already have groundbreaking consequences in algebraic circuit complexity by Valiant’s depth reduction.
Example 1: identity matrix
Consider the identity matrix $I^n$: it has full rank, so that seems like a good start. We can make it rank $r$ by changing $n-r$ of the ones into zeros, so it cannot have rigidity more than $n-r$.
But it turns out it does have rigidity $n-r$. Indeed, if its rigidity was less than $n-r$, then you could decompose it as the sum $I^n = A + B$ such that $A$ has $<n-r$ nonzero elements and $\rank(B) \leq r$. But this is impossible because we’d have
\[\rank(I^n) = \rank(A+B) \leq \rank(A)+\rank(B) < (n-r) + r = n\]
(note that this “subadditivity” of rank is also used to give lower bounds on communication complexity, see Monochromatic rectangles#The rank method).
Example 2: Midrijānis
There is a sense in which $I^n$ is “overkill” when $r$ is small: $I^n$ offers you rank $n$ to start with, which is much more than you actually need. Midrijānis’s idea was that you can do better if you build your matrix from smaller identity matrices $I^{2r}$.
Concretely, let $M_{n,2r}$ be the matrix that is formed by putting together $(n/2r)^2$ identity matrices $I^{2r}$ into a big $n \times n$ matrix. Then $R_r(M_{n,2r}) = n^2/4r$. Indeed, if any of the $(n/2r)^2$ blocks retains rank $>r$, then the whole thing will have rank $>r$, so by the same reasoning as before, if you want to decrease the rank to $r$, you need to change at least $2r-r = r$ elements in each of the blocks, for a total of $(n/2r)^2 \cdot r = n^2/4r$ changes.
However, for $r = \eps n$, which is the regime we’re interested about, the rigidity is still only linear.
Example 3: that construction that gains a log n factor
TODO: haven’t learned this yet