$\require{mathtools}
\newcommand{\nc}{\newcommand}
%
%%% GENERIC MATH %%%
%
% Environments
\newcommand{\al}[1]{\begin{align}#1\end{align}} % need this for \tag{} to work
\renewcommand{\r}{\mathrm} % BAD!! does cursed things with accents :((
\renewcommand{\t}{\textrm}
\newcommand{\either}[1]{\begin{cases}#1\end{cases}}
%
% Delimiters
% (I needed to create my own because the MathJax version of \DeclarePairedDelimiter doesn't have \mathopen{} and that messes up the spacing)
% .. one-part
\newcommand{\p}[1]{\mathopen{}\left( #1 \right)}
\renewcommand{\P}[1]{^{\p{#1}}}
\renewcommand{\b}[1]{\mathopen{}\left[ #1 \right]}
\newcommand{\lopen}[1]{\mathopen{}\left( #1 \right]}
\newcommand{\ropen}[1]{\mathopen{}\left[ #1 \right)}
\newcommand{\set}[1]{\mathopen{}\left\{ #1 \right\}}
\newcommand{\abs}[1]{\mathopen{}\left\lvert #1 \right\rvert}
\newcommand{\floor}[1]{\mathopen{}\left\lfloor #1 \right\rfloor}
\newcommand{\ceil}[1]{\mathopen{}\left\lceil #1 \right\rceil}
\newcommand{\round}[1]{\mathopen{}\left\lfloor #1 \right\rceil}
\newcommand{\inner}[1]{\mathopen{}\left\langle #1 \right\rangle}
\newcommand{\norm}[1]{\mathopen{}\left\lVert #1 \strut \right\rVert}
\newcommand{\frob}[1]{\norm{#1}_\mathrm{F}}
\newcommand{\mix}[1]{\mathopen{}\left\lfloor #1 \right\rceil}
%% .. two-part
\newcommand{\inco}[2]{#1 \mathop{}\middle|\mathop{} #2}
\newcommand{\co}[2]{ {\left.\inco{#1}{#2}\right.}}
\newcommand{\cond}{\co} % deprecated
\newcommand{\pco}[2]{\p{\inco{#1}{#2}}}
\newcommand{\bco}[2]{\b{\inco{#1}{#2}}}
\newcommand{\setco}[2]{\set{\inco{#1}{#2}}}
\newcommand{\at}[2]{ {\left.#1\strut\right|_{#2}}}
\newcommand{\pat}[2]{\p{\at{#1}{#2}}}
\newcommand{\bat}[2]{\b{\at{#1}{#2}}}
\newcommand{\para}[2]{#1\strut \mathop{}\middle\|\mathop{} #2}
\newcommand{\ppa}[2]{\p{\para{#1}{#2}}}
\newcommand{\pff}[2]{\p{\ff{#1}{#2}}}
\newcommand{\bff}[2]{\b{\ff{#1}{#2}}}
\newcommand{\bffco}[4]{\bff{\cond{#1}{#2}}{\cond{#3}{#4}}}
\newcommand{\sm}[1]{\p{\begin{smallmatrix}#1\end{smallmatrix}}}
%
% Greek
\newcommand{\eps}{\epsilon}
\newcommand{\veps}{\varepsilon}
\newcommand{\vpi}{\varpi}
% the following cause issues with real LaTeX tho :/ maybe consider naming it \fhi instead?
\let\fi\phi % because it looks like an f
\let\phi\varphi % because it looks like a p
\renewcommand{\th}{\theta}
\newcommand{\Th}{\Theta}
\newcommand{\om}{\omega}
\newcommand{\Om}{\Omega}
%
% Miscellaneous
\newcommand{\LHS}{\mathrm{LHS}}
\newcommand{\RHS}{\mathrm{RHS}}
\DeclareMathOperator{\cst}{const}
% .. operators
\DeclareMathOperator{\poly}{poly}
\DeclareMathOperator{\polylog}{polylog}
\DeclareMathOperator{\quasipoly}{quasipoly}
\DeclareMathOperator{\negl}{negl}
\DeclareMathOperator*{\argmin}{arg\thinspace min}
\DeclareMathOperator*{\argmax}{arg\thinspace max}
\DeclareMathOperator{\diag}{diag}
% .. functions
\DeclareMathOperator{\id}{id}
\DeclareMathOperator{\sign}{sign}
\DeclareMathOperator{\step}{step}
\DeclareMathOperator{\err}{err}
\DeclareMathOperator{\ReLU}{ReLU}
\DeclareMathOperator{\softmax}{softmax}
% .. analysis
\let\d\undefined
\newcommand{\d}{\operatorname{d}\mathopen{}}
\newcommand{\dd}[1]{\operatorname{d}^{#1}\mathopen{}}
\newcommand{\df}[2]{ {\f{\d #1}{\d #2}}}
\newcommand{\ds}[2]{ {\sl{\d #1}{\d #2}}}
\newcommand{\ddf}[3]{ {\f{\dd{#1} #2}{\p{\d #3}^{#1}}}}
\newcommand{\dds}[3]{ {\sl{\dd{#1} #2}{\p{\d #3}^{#1}}}}
\renewcommand{\part}{\partial}
\newcommand{\ppart}[1]{\part^{#1}}
\newcommand{\partf}[2]{\f{\part #1}{\part #2}}
\newcommand{\parts}[2]{\sl{\part #1}{\part #2}}
\newcommand{\ppartf}[3]{ {\f{\ppart{#1} #2}{\p{\part #3}^{#1}}}}
\newcommand{\pparts}[3]{ {\sl{\ppart{#1} #2}{\p{\part #3}^{#1}}}}
\newcommand{\grad}[1]{\mathop{\nabla\!_{#1}}}
% .. sets
\newcommand{\es}{\emptyset}
\newcommand{\N}{\mathbb{N}}
\newcommand{\Z}{\mathbb{Z}}
\newcommand{\R}{\mathbb{R}}
\newcommand{\Rge}{\R_{\ge 0}}
\newcommand{\Rgt}{\R_{> 0}}
\newcommand{\C}{\mathbb{C}}
\newcommand{\F}{\mathbb{F}}
\newcommand{\zo}{\set{0,1}}
\newcommand{\pmo}{\set{\pm 1}}
\newcommand{\zpmo}{\set{0,\pm 1}}
% .... set operations
\newcommand{\sse}{\subseteq}
\newcommand{\out}{\not\in}
\newcommand{\minus}{\setminus}
\newcommand{\inc}[1]{\union \set{#1}} % "including"
\newcommand{\exc}[1]{\setminus \set{#1}} % "except"
% .. over and under
\renewcommand{\ss}[1]{_{\substack{#1}}}
\newcommand{\OB}{\overbrace}
\newcommand{\ob}[2]{\OB{#1}^\t{#2}}
\newcommand{\UB}{\underbrace}
\newcommand{\ub}[2]{\UB{#1}_\t{#2}}
\newcommand{\ol}{\overline}
\newcommand{\tld}{\widetilde} % deprecated
\renewcommand{\~}{\widetilde}
\newcommand{\HAT}{\widehat} % deprecated
\renewcommand{\^}{\widehat}
\newcommand{\rt}[1]{ {\sqrt{#1}}}
\newcommand{\for}[2]{_{#1=1}^{#2}}
\newcommand{\sfor}{\sum\for}
\newcommand{\pfor}{\prod\for}
% .... two-part
\newcommand{\f}{\frac}
\renewcommand{\sl}[2]{#1 /\mathopen{}#2}
\newcommand{\ff}[2]{\mathchoice{\begin{smallmatrix}\displaystyle\vphantom{\p{#1}}#1\\[-0.05em]\hline\\[-0.05em]\hline\displaystyle\vphantom{\p{#2}}#2\end{smallmatrix}}{\begin{smallmatrix}\vphantom{\p{#1}}#1\\[-0.1em]\hline\\[-0.1em]\hline\vphantom{\p{#2}}#2\end{smallmatrix}}{\begin{smallmatrix}\vphantom{\p{#1}}#1\\[-0.1em]\hline\\[-0.1em]\hline\vphantom{\p{#2}}#2\end{smallmatrix}}{\begin{smallmatrix}\vphantom{\p{#1}}#1\\[-0.1em]\hline\\[-0.1em]\hline\vphantom{\p{#2}}#2\end{smallmatrix}}}
% .. arrows
\newcommand{\from}{\leftarrow}
\DeclareMathOperator*{\<}{\!\;\longleftarrow\;\!}
\let\>\undefined
\DeclareMathOperator*{\>}{\!\;\longrightarrow\;\!}
\let\-\undefined
\DeclareMathOperator*{\-}{\!\;\longleftrightarrow\;\!}
\newcommand{\so}{\implies}
% .. operators and relations
\renewcommand{\*}{\cdot}
\newcommand{\x}{\times}
\newcommand{\ox}{\otimes}
\newcommand{\OX}[1]{^{\ox #1}}
\newcommand{\sr}{\stackrel}
\newcommand{\ce}{\coloneqq}
\newcommand{\ec}{\eqqcolon}
\newcommand{\ap}{\approx}
\newcommand{\ls}{\lesssim}
\newcommand{\gs}{\gtrsim}
% .. punctuation and spacing
\renewcommand{\.}[1]{#1\dots#1}
\newcommand{\ts}{\thinspace}
\newcommand{\q}{\quad}
\newcommand{\qq}{\qquad}
%
%
%%% SPECIALIZED MATH %%%
%
% Logic and bit operations
\newcommand{\fa}{\forall}
\newcommand{\ex}{\exists}
\renewcommand{\and}{\wedge}
\newcommand{\AND}{\bigwedge}
\renewcommand{\or}{\vee}
\newcommand{\OR}{\bigvee}
\newcommand{\xor}{\oplus}
\newcommand{\XOR}{\bigoplus}
\newcommand{\union}{\cup}
\newcommand{\dunion}{\sqcup}
\newcommand{\inter}{\cap}
\newcommand{\UNION}{\bigcup}
\newcommand{\DUNION}{\bigsqcup}
\newcommand{\INTER}{\bigcap}
\newcommand{\comp}{\overline}
\newcommand{\true}{\r{true}}
\newcommand{\false}{\r{false}}
\newcommand{\tf}{\set{\true,\false}}
\DeclareMathOperator{\One}{\mathbb{1}}
\DeclareMathOperator{\1}{\mathbb{1}} % use \mathbbm instead if using real LaTeX
\DeclareMathOperator{\LSB}{LSB}
%
% Linear algebra
\newcommand{\spn}{\mathrm{span}} % do NOT use \span because it causes misery with amsmath
\DeclareMathOperator{\rank}{rank}
\DeclareMathOperator{\proj}{proj}
\DeclareMathOperator{\dom}{dom}
\DeclareMathOperator{\Img}{Im}
\DeclareMathOperator{\tr}{tr}
\DeclareMathOperator{\perm}{perm}
\DeclareMathOperator{\haf}{haf}
\newcommand{\transp}{\mathsf{T}}
\newcommand{\T}{^\transp}
\newcommand{\par}{\parallel}
% .. named tensors
\newcommand{\namedtensorstrut}{\vphantom{fg}} % milder than \mathstrut
\newcommand{\name}[1]{\mathsf{\namedtensorstrut #1}}
\newcommand{\nbin}[2]{\mathbin{\underset{\substack{#1}}{\namedtensorstrut #2}}}
\newcommand{\ndot}[1]{\nbin{#1}{\odot}}
\newcommand{\ncat}[1]{\nbin{#1}{\oplus}}
\newcommand{\nsum}[1]{\sum\limits_{\substack{#1}}}
\newcommand{\nfun}[2]{\mathop{\underset{\substack{#1}}{\namedtensorstrut\mathrm{#2}}}}
\newcommand{\ndef}[2]{\newcommand{#1}{\name{#2}}}
\newcommand{\nt}[1]{^{\transp(#1)}}
%
% Probability
\newcommand{\tri}{\triangle}
\newcommand{\Normal}{\mathcal{N}}
\newcommand{\Exp}{\mathcal{Exp}}
% .. operators
\DeclareMathOperator{\supp}{supp}
\let\Pr\undefined
\DeclareMathOperator*{\Pr}{Pr}
\DeclareMathOperator*{\G}{\mathbb{G}}
\DeclareMathOperator*{\Odds}{Od}
\DeclareMathOperator*{\E}{E}
\DeclareMathOperator*{\Var}{Var}
\DeclareMathOperator*{\Cov}{Cov}
\DeclareMathOperator*{\K}{K}
\DeclareMathOperator*{\corr}{corr}
\DeclareMathOperator*{\median}{median}
\DeclareMathOperator*{\maj}{maj}
% ... information theory
\let\H\undefined
\DeclareMathOperator*{\H}{H}
\DeclareMathOperator*{\I}{I}
\DeclareMathOperator*{\D}{D}
\DeclareMathOperator*{\KL}{KL}
% .. other divergences
\newcommand{\dTV}{d_{\mathrm{TV}}}
\newcommand{\dHel}{d_{\mathrm{Hel}}}
\newcommand{\dJS}{d_{\mathrm{JS}}}
%
% Polynomials
\DeclareMathOperator{\He}{He}
\DeclareMathOperator{\coeff}{coeff}
%
%%% SPECIALIZED COMPUTER SCIENCE %%%
%
% Complexity classes
% .. keywords
\newcommand{\coclass}{\mathsf{co}}
\newcommand{\Prom}{\mathsf{Promise}}
% .. classical
\newcommand{\PTIME}{\mathsf{P}}
\newcommand{\NP}{\mathsf{NP}}
\newcommand{\coNP}{\coclass\NP}
\newcommand{\PH}{\mathsf{PH}}
\newcommand{\PSPACE}{\mathsf{PSPACE}}
\renewcommand{\L}{\mathsf{L}}
\newcommand{\EXP}{\mathsf{EXP}}
\newcommand{\NEXP}{\mathsf{NEXP}}
% .. probabilistic
\newcommand{\formost}{\mathsf{Я}}
\newcommand{\RP}{\mathsf{RP}}
\newcommand{\BPP}{\mathsf{BPP}}
\newcommand{\ZPP}{\mathsf{ZPP}}
\newcommand{\MA}{\mathsf{MA}}
\newcommand{\AM}{\mathsf{AM}}
\newcommand{\IP}{\mathsf{IP}}
\newcommand{\RL}{\mathsf{RL}}
% .. circuits
\newcommand{\NC}{\mathsf{NC}}
\newcommand{\AC}{\mathsf{AC}}
\newcommand{\ACC}{\mathsf{ACC}}
\newcommand{\ThrC}{\mathsf{TC}}
\newcommand{\Ppoly}{\mathsf{P}/\poly}
\newcommand{\Lpoly}{\mathsf{L}/\poly}
% .. resources
\newcommand{\TIME}{\mathsf{TIME}}
\newcommand{\NTIME}{\mathsf{NTIME}}
\newcommand{\SPACE}{\mathsf{SPACE}}
\newcommand{\TISP}{\mathsf{TISP}}
\newcommand{\SIZE}{\mathsf{SIZE}}
% .. custom
\newcommand{\NCP}{\mathsf{NCP}}
%
% Boolean analysis
\newcommand{\harpoon}{\!\upharpoonright\!}
\newcommand{\rr}[2]{#1\harpoon_{#2}}
\newcommand{\Fou}[1]{\widehat{#1}}
\DeclareMathOperator{\Ind}{\mathrm{Ind}}
\DeclareMathOperator{\Inf}{\mathrm{Inf}}
\newcommand{\Der}[1]{\operatorname{D}_{#1}\mathopen{}}
% \newcommand{\Exp}[1]{\operatorname{E}_{#1}\mathopen{}}
\DeclareMathOperator{\Stab}{\mathrm{Stab}}
\DeclareMathOperator{\Tau}{T}
\DeclareMathOperator{\sens}{\mathrm{s}}
\DeclareMathOperator{\bsens}{\mathrm{bs}}
\DeclareMathOperator{\fbsens}{\mathrm{fbs}}
\DeclareMathOperator{\Cert}{\mathrm{C}}
\DeclareMathOperator{\DT}{\mathrm{DT}}
\DeclareMathOperator{\CDT}{\mathrm{CDT}} % canonical
\DeclareMathOperator{\ECDT}{\mathrm{ECDT}}
\DeclareMathOperator{\CDTv}{\mathrm{CDT_{vars}}}
\DeclareMathOperator{\ECDTv}{\mathrm{ECDT_{vars}}}
\DeclareMathOperator{\CDTt}{\mathrm{CDT_{terms}}}
\DeclareMathOperator{\ECDTt}{\mathrm{ECDT_{terms}}}
\DeclareMathOperator{\CDTw}{\mathrm{CDT_{weighted}}}
\DeclareMathOperator{\ECDTw}{\mathrm{ECDT_{weighted}}}
\DeclareMathOperator{\AvgDT}{\mathrm{AvgDT}}
\DeclareMathOperator{\PDT}{\mathrm{PDT}} % partial decision tree
\DeclareMathOperator{\DTsize}{\mathrm{DT_{size}}}
\DeclareMathOperator{\W}{\mathbf{W}}
% .. functions (small caps sadly doesn't work)
\DeclareMathOperator{\Par}{\mathrm{Par}}
\DeclareMathOperator{\Maj}{\mathrm{Maj}}
\DeclareMathOperator{\HW}{\mathrm{HW}}
\DeclareMathOperator{\Thr}{\mathrm{Thr}}
\DeclareMathOperator{\Tribes}{\mathrm{Tribes}}
\DeclareMathOperator{\RotTribes}{\mathrm{RotTribes}}
\DeclareMathOperator{\CycleRun}{\mathrm{CycleRun}}
\DeclareMathOperator{\SAT}{\mathrm{SAT}}
\DeclareMathOperator{\UniqueSAT}{\mathrm{UniqueSAT}}
%
% Dynamic optimality
\newcommand{\OPT}{\mathsf{OPT}}
\newcommand{\Alt}{\mathsf{Alt}}
\newcommand{\Funnel}{\mathsf{Funnel}}
%
% Alignment
\DeclareMathOperator{\Amp}{\mathrm{Amp}}
%
%%% TYPESETTING %%%
%
% In "text"
\newcommand{\heart}{\heartsuit}
\newcommand{\nth}{^\t{th}}
\newcommand{\degree}{^\circ}
\newcommand{\qu}[1]{\text{``}#1\text{''}}
% remove these last two if using real LaTeX
\newcommand{\qed}{\blacksquare}
\newcommand{\qedhere}{\tag*{$\blacksquare$}}
%
% Fonts
% .. bold
\newcommand{\BA}{\boldsymbol{A}}
\newcommand{\BB}{\boldsymbol{B}}
\newcommand{\BC}{\boldsymbol{C}}
\newcommand{\BD}{\boldsymbol{D}}
\newcommand{\BE}{\boldsymbol{E}}
\newcommand{\BF}{\boldsymbol{F}}
\newcommand{\BG}{\boldsymbol{G}}
\newcommand{\BH}{\boldsymbol{H}}
\newcommand{\BI}{\boldsymbol{I}}
\newcommand{\BJ}{\boldsymbol{J}}
\newcommand{\BK}{\boldsymbol{K}}
\newcommand{\BL}{\boldsymbol{L}}
\newcommand{\BM}{\boldsymbol{M}}
\newcommand{\BN}{\boldsymbol{N}}
\newcommand{\BO}{\boldsymbol{O}}
\newcommand{\BP}{\boldsymbol{P}}
\newcommand{\BQ}{\boldsymbol{Q}}
\newcommand{\BR}{\boldsymbol{R}}
\newcommand{\BS}{\boldsymbol{S}}
\newcommand{\BT}{\boldsymbol{T}}
\newcommand{\BU}{\boldsymbol{U}}
\newcommand{\BV}{\boldsymbol{V}}
\newcommand{\BW}{\boldsymbol{W}}
\newcommand{\BX}{\boldsymbol{X}}
\newcommand{\BY}{\boldsymbol{Y}}
\newcommand{\BZ}{\boldsymbol{Z}}
\newcommand{\Ba}{\boldsymbol{a}}
\newcommand{\Bb}{\boldsymbol{b}}
\newcommand{\Bc}{\boldsymbol{c}}
\newcommand{\Bd}{\boldsymbol{d}}
\newcommand{\Be}{\boldsymbol{e}}
\newcommand{\Bf}{\boldsymbol{f}}
\newcommand{\Bg}{\boldsymbol{g}}
\newcommand{\Bh}{\boldsymbol{h}}
\newcommand{\Bi}{\boldsymbol{i}}
\newcommand{\Bj}{\boldsymbol{j}}
\newcommand{\Bk}{\boldsymbol{k}}
\newcommand{\Bl}{\boldsymbol{l}}
\newcommand{\Bm}{\boldsymbol{m}}
\newcommand{\Bn}{\boldsymbol{n}}
\newcommand{\Bo}{\boldsymbol{o}}
\newcommand{\Bp}{\boldsymbol{p}}
\newcommand{\Bq}{\boldsymbol{q}}
\newcommand{\Br}{\boldsymbol{r}}
\newcommand{\Bs}{\boldsymbol{s}}
\newcommand{\Bt}{\boldsymbol{t}}
\newcommand{\Bu}{\boldsymbol{u}}
\newcommand{\Bv}{\boldsymbol{v}}
\newcommand{\Bw}{\boldsymbol{w}}
\newcommand{\Bx}{\boldsymbol{x}}
\newcommand{\By}{\boldsymbol{y}}
\newcommand{\Bz}{\boldsymbol{z}}
\newcommand{\Balpha}{\boldsymbol{\alpha}}
\newcommand{\Bbeta}{\boldsymbol{\beta}}
\newcommand{\Bgamma}{\boldsymbol{\gamma}}
\newcommand{\Bdelta}{\boldsymbol{\delta}}
\newcommand{\Beps}{\boldsymbol{\eps}}
\newcommand{\Bveps}{\boldsymbol{\veps}}
\newcommand{\Bzeta}{\boldsymbol{\zeta}}
\newcommand{\Beta}{\boldsymbol{\eta}}
\newcommand{\Btheta}{\boldsymbol{\theta}}
\newcommand{\Bth}{\boldsymbol{\th}}
\newcommand{\Biota}{\boldsymbol{\iota}}
\newcommand{\Bkappa}{\boldsymbol{\kappa}}
\newcommand{\Blambda}{\boldsymbol{\lambda}}
\newcommand{\Bmu}{\boldsymbol{\mu}}
\newcommand{\Bnu}{\boldsymbol{\nu}}
\newcommand{\Bxi}{\boldsymbol{\xi}}
\newcommand{\Bpi}{\boldsymbol{\pi}}
\newcommand{\Bvpi}{\boldsymbol{\vpi}}
\newcommand{\Brho}{\boldsymbol{\rho}}
\newcommand{\Bsigma}{\boldsymbol{\sigma}}
\newcommand{\Btau}{\boldsymbol{\tau}}
\newcommand{\Bupsilon}{\boldsymbol{\upsilon}}
\newcommand{\Bphi}{\boldsymbol{\phi}}
\newcommand{\Bfi}{\boldsymbol{\fi}}
\newcommand{\Bchi}{\boldsymbol{\chi}}
\newcommand{\Bpsi}{\boldsymbol{\psi}}
\newcommand{\Bom}{\boldsymbol{\om}}
% .. calligraphic
\newcommand{\CA}{\mathcal{A}}
\newcommand{\CB}{\mathcal{B}}
\newcommand{\CC}{\mathcal{C}}
\newcommand{\CD}{\mathcal{D}}
\newcommand{\CE}{\mathcal{E}}
\newcommand{\CF}{\mathcal{F}}
\newcommand{\CG}{\mathcal{G}}
\newcommand{\CH}{\mathcal{H}}
\newcommand{\CI}{\mathcal{I}}
\newcommand{\CJ}{\mathcal{J}}
\newcommand{\CK}{\mathcal{K}}
\newcommand{\CL}{\mathcal{L}}
\newcommand{\CM}{\mathcal{M}}
\newcommand{\CN}{\mathcal{N}}
\newcommand{\CO}{\mathcal{O}}
\newcommand{\CP}{\mathcal{P}}
\newcommand{\CQ}{\mathcal{Q}}
\newcommand{\CR}{\mathcal{R}}
\newcommand{\CS}{\mathcal{S}}
\newcommand{\CT}{\mathcal{T}}
\newcommand{\CU}{\mathcal{U}}
\newcommand{\CV}{\mathcal{V}}
\newcommand{\CW}{\mathcal{W}}
\newcommand{\CX}{\mathcal{X}}
\newcommand{\CY}{\mathcal{Y}}
\newcommand{\CZ}{\mathcal{Z}}
% .. typewriter
\newcommand{\TA}{\mathtt{A}}
\newcommand{\TB}{\mathtt{B}}
\newcommand{\TC}{\mathtt{C}}
\newcommand{\TD}{\mathtt{D}}
\newcommand{\TE}{\mathtt{E}}
\newcommand{\TF}{\mathtt{F}}
\newcommand{\TG}{\mathtt{G}}
\renewcommand{\TH}{\mathtt{H}}
\newcommand{\TI}{\mathtt{I}}
\newcommand{\TJ}{\mathtt{J}}
\newcommand{\TK}{\mathtt{K}}
\newcommand{\TL}{\mathtt{L}}
\newcommand{\TM}{\mathtt{M}}
\newcommand{\TN}{\mathtt{N}}
\newcommand{\TO}{\mathtt{O}}
\newcommand{\TP}{\mathtt{P}}
\newcommand{\TQ}{\mathtt{Q}}
\newcommand{\TR}{\mathtt{R}}
\newcommand{\TS}{\mathtt{S}}
\newcommand{\TT}{\mathtt{T}}
\newcommand{\TU}{\mathtt{U}}
\newcommand{\TV}{\mathtt{V}}
\newcommand{\TW}{\mathtt{W}}
\newcommand{\TX}{\mathtt{X}}
\newcommand{\TY}{\mathtt{Y}}
\newcommand{\TZ}{\mathtt{Z}}
%
% LEVELS OF CLOSENESS (basically deprecated)
\newcommand{\scirc}[1]{\sr{\circ}{#1}}
\newcommand{\sdot}[1]{\sr{.}{#1}}
\newcommand{\slog}[1]{\sr{\log}{#1}}
\newcommand{\createClosenessLevels}[7]{
\newcommand{#2}{\mathrel{(#1)}}
\newcommand{#3}{\mathrel{#1}}
\newcommand{#4}{\mathrel{#1\!\!#1}}
\newcommand{#5}{\mathrel{#1\!\!#1\!\!#1}}
\newcommand{#6}{\mathrel{(\sdot{#1})}}
\newcommand{#7}{\mathrel{(\slog{#1})}}
}
\let\lt\undefined
\let\gt\undefined
% .. vanilla versions (is it within a constant?)
\newcommand{\ez}{\scirc=}
\newcommand{\eq}{\simeq}
\newcommand{\eqq}{\mathrel{\eq\!\!\eq}}
\newcommand{\eqqq}{\mathrel{\eq\!\!\eq\!\!\eq}}
\newcommand{\lez}{\scirc\le}
\renewcommand{\lq}{\preceq}
\newcommand{\lqq}{\mathrel{\lq\!\!\lq}}
\newcommand{\lqqq}{\mathrel{\lq\!\!\lq\!\!\lq}}
\newcommand{\gez}{\scirc\ge}
\newcommand{\gq}{\succeq}
\newcommand{\gqq}{\mathrel{\gq\!\!\gq}}
\newcommand{\gqqq}{\mathrel{\gq\!\!\gq\!\!\gq}}
\newcommand{\lz}{\scirc<}
\newcommand{\lt}{\prec}
\newcommand{\ltt}{\mathrel{\lt\!\!\lt}}
\newcommand{\lttt}{\mathrel{\lt\!\!\lt\!\!\lt}}
\newcommand{\gz}{\scirc>}
\newcommand{\gt}{\succ}
\newcommand{\gtt}{\mathrel{\gt\!\!\gt}}
\newcommand{\gttt}{\mathrel{\gt\!\!\gt\!\!\gt}}
% .. dotted versions (is it equal in the limit?)
\newcommand{\ed}{\sdot=}
\newcommand{\eqd}{\sdot\eq}
\newcommand{\eqqd}{\sdot\eqq}
\newcommand{\eqqqd}{\sdot\eqqq}
\newcommand{\led}{\sdot\le}
\newcommand{\lqd}{\sdot\lq}
\newcommand{\lqqd}{\sdot\lqq}
\newcommand{\lqqqd}{\sdot\lqqq}
\newcommand{\ged}{\sdot\ge}
\newcommand{\gqd}{\sdot\gq}
\newcommand{\gqqd}{\sdot\gqq}
\newcommand{\gqqqd}{\sdot\gqqq}
\newcommand{\ld}{\sdot<}
\newcommand{\ltd}{\sdot\lt}
\newcommand{\lttd}{\sdot\ltt}
\newcommand{\ltttd}{\sdot\lttt}
\newcommand{\gd}{\sdot>}
\newcommand{\gtd}{\sdot\gt}
\newcommand{\gttd}{\sdot\gtt}
\newcommand{\gtttd}{\sdot\gttt}
% .. log versions (is it equal up to log?)
\newcommand{\elog}{\slog=}
\newcommand{\eqlog}{\slog\eq}
\newcommand{\eqqlog}{\slog\eqq}
\newcommand{\eqqqlog}{\slog\eqqq}
\newcommand{\lelog}{\slog\le}
\newcommand{\lqlog}{\slog\lq}
\newcommand{\lqqlog}{\slog\lqq}
\newcommand{\lqqqlog}{\slog\lqqq}
\newcommand{\gelog}{\slog\ge}
\newcommand{\gqlog}{\slog\gq}
\newcommand{\gqqlog}{\slog\gqq}
\newcommand{\gqqqlog}{\slog\gqqq}
\newcommand{\llog}{\slog<}
\newcommand{\ltlog}{\slog\lt}
\newcommand{\lttlog}{\slog\ltt}
\newcommand{\ltttlog}{\slog\lttt}
\newcommand{\glog}{\slog>}
\newcommand{\gtlog}{\slog\gt}
\newcommand{\gttlog}{\slog\gtt}
\newcommand{\gtttlog}{\slog\gttt}$
Adapted from lectures 10 and 11 of Ryan O’Donnell’s Fall 2017 graduate complexity theory class at CMU.
In Buying randomness with quantifiers, we saw that in some cases, we can trade randomness for $\forall$ or $\exists$ quantifiers, proving that $\BPP$ is in $\Ppoly$ and $\Sigma_2\PTIME$. In this note, we extract the essence of those two proofs and apply the tricks more generally, with a focus on Arthur-Merlin complexity classes.
An interlude on quantifier notation
Since both of the two tricks we’ve seen allowed us to “play with the quantifiers” in the definitions of complexity classes in specific ways, it would be useful to make this more systematic by encapsulating the definitions of many complexity classes using quantifiers only.
For example, $\Sigma_2\PTIME$ corresponds to the languages $L$ for which there is a verifier $V$ such that
- if $x \in L$, then $\exists y, \forall z: V(x,y,z) = 1$;
- if $x \not\in L$, then $\forall y, \exists z : V(x,y,z) = 0$.
Because the quantifiers are $\exists \forall$ in one case and $\forall\exists$ in the other, we will simply call this class “$\exists\forall/\forall\exists$”. In general, by “$Q_1, \ldots Q_k/Q'_1, \ldots, Q'_k$” (where $Q_i, Q'_i$ are quantifiers in $\exists,\forall,\formost$), we mean the class of all languages $L$ for which there is a verifier $V$ such that
- if $x \in L$, then $Q_1y_1, \ldots, Q_ky_k: V(x,y_1, \ldots, y_k) = 1$;
- if $x \not\in L$, then $Q'_1y_y, \ldots, Q'_ky_k : V(x,y_1, \ldots, y_k) = 0$.
As such, the reader is encourage to verify that $\PTIME = /$, $\NP = \exists/\forall$, $\coclass\NP = \forall/\exists$, $\Pi_2\PTIME = \forall\exists/\exists\forall$, $\BPP = \formost/\formost$, $\RP = \formost/\forall$, $\coclass\RP = \forall/\formost$, $\MA = \exists\formost/\forall\formost$, and $\AM = \formost\exists/\formost\forall$. In general, to take the “$\coclass$” of a class, you simply swap both sides of the slash.
The tricks in our hands
Let’s recall the tools at our disposal: three easy ones, and the two we just proved.
This one is purely logical: we can always turn a $\forall$ into a $\formost$, and a $\formost$ into $\exists$, because this only weakens the guarantee. In words: “if all, then most, and if most, then some”. As an example, this shows that $\RP = \formost/\forall \sse \exists/\forall = \NP$.
Specialize: $\exists\forall \Rightarrow \forall\exists$
Another purely logical one: we can swap $\exists\forall$ into $\forall\exists$, because all this does is to allow the $\exists$ quantifier to specify more. In words: “if a song is liked by everyone, then everyone has a song that they like”.
In fact, this principle also extends well to $\formost$, if you think of $\formost$ as sort of “halfway in between $\exists$ and $\forall$”:
- you can swap $\exists \formost \rightarrow \formost \exists$, because “if a song is liked by most people, then most people have a song that they like”;
- you can swap $\formost\forall \rightarrow \forall \formost$, because “if most people like all songs, then all songs are liked by most people”.
Combine: $\forall\forall = \forall$
If we have the same quantifier twice, then we can reduce it to a single quantifier. For example, suppose we were to define a dumb class $\exists\exists/\forall\forall$, i.e.
- if $x \in L$, then $\exists y, \exists z: V(x,y,z) = 1$;
- if $x \not\in L$, then $\forall y, \forall z : V(x,y,z) = 0$.
Then we could just combine strings $y$ and $z$ together:
- if $x \in L$, then $\exists (y,z): V(x,y,z) = 1$;
- if $x \not\in L$, then $\forall (y,z) : V(x,y,z) = 0$.
And this is now functionally equivalent to $\exists/\forall = \NP$.
The key of the proof of $\BPP \sse \Ppoly$ was to boost the success probability so much that we can go from “for all inputs $x$, most random strings $r$ give the correct answer” to “most random strings $r$ give the correct answer for all inputs $x$” by a union bound. In general, we can always flip $\forall\formost$ into $\formost\forall$ (even though this is the “wrong” direction in terms of direct implication).
In words: “if there’s more songs than people, and everyone likes all but a handful of songs, then most songs are liked by literally everyone”.
In the proof that $\BPP \sse \Sigma_2\PTIME$, we saw that if we have a set $S$ of random strings covering almost all of $\zo^s$, then the union of random offset copies $(S \xor d^{(1)}) \union \cdots \union (S \xor d^{(s)})$ covers all of $\zo^s$ with high probability, while if $S$ contains almost none of $\zo^s$, then no matter what offsets you choose, the offset copies will still cover only a tiny fraction of $\zo^s$. That is, after boosting the success probability,
- $\formost r : V(x,r)=1$ implies $\formost d^{(1)}, \ldots, d^{(s)}, \forall r : V(x,r \xor d^{(1)}) \or \cdots \or V(x,r \xor d^{(s)}) = 1$;
- $\formost r : V(x,r)=0$ implies $\forall d^{(1)}, \ldots, d^{(s)}, \formost r : V(x,r \xor d^{(1)}) \or \cdots \or V(x,r \xor d^{(s)}) = 0$.
So we can transform $\formost/\formost$ into $\formost\forall/\forall\formost$.
In words: “an almost full jar will typically look full if you squint, but an almost empty jar will always look mostly empty no matter how you squint”.
Also, by taking the “$\coclass$” of both sides, we also get $\formost/\formost \rightarrow \forall\formost/\formost\forall$. This corresponds to taking the intersection of the offset copies $(S \xor d^{(1)}) \inter \cdots \inter (S \xor d^{(s)})$ instead of the union (and therefore the AND instead of the OR). This ensures that when $S$ covers almost all of $\zo^s$, the intersection is still big, while if $S$ contains almost none of $\zo^s$, the intersection will be completely empty with high probability.
A slurry of corollaries
We’ve done all the hard thinking work, now we get to play around with quantifiers!
A alternative characterization of $\BPP$
The proof that $\BPP \sse \Sigma_2\PTIME$ that we saw before really went through an intermediate class $\formost\forall/\forall\formost$:
\[\BPP = \formost/\formost \stackrel{\text{squint}}{\sse} \formost\forall/\forall\formost \stackrel{\text{weaken}}{\sse} \exists\forall/\forall\exists = \Sigma^2\PTIME.\]
As it turns out, $\formost\forall/\forall\formost$ is equal to $\BPP$, since
\[
\formost\forall/\forall\formost \stackrel{\text{weaken}}\sse \formost\formost/\formost\formost \stackrel{\text{combine}}= \formost/\formost = \BPP.
\]
One-sided error for $\MA$ and $\AM$
Both $\MA$ and $\AM$ correspond to two-round proof protocols between Arthur, a weak but honest mortal with the power of $\BPP$, and Merlin, a powerful but untrustworthy wizard with unbounded computation power (Merlin kind of plays the role of $\NP$ here).
The two classes vary only in who goes first:
- In $\MA \ce \exists\formost/\forall\formost$, Merlin first sends a purported “proof” that $x \in L$, then Arthur uses randomness to “verify” the proof.
- In $\AM \ce \formost\exists/\formost\forall$, Arthur first uses randomness to create an $\NP$-type “challenge” for Merlin (e.g. a SAT instance), then Merlin tries to find a “solution” to the challenge.
The same squinting trick that gives “absolute guarantees” for $\BPP$ at the cost of an extra quantifier can also give absolute guarantees for $\MA$ and $\AM$, but this time for free: Merlin’s $\exists/\forall$ quantifier can absorb one of the two quantifiers that appear.
Formally,
\[
\MA = \exists\formost/\forall\formost \stackrel{\text{squint}}\sse \exists(\formost\forall)/\forall(\forall\formost )\stackrel{\text{weaken}}\sse \exists\exists\forall/\forall\forall\formost \stackrel{\text{combine}}= \exists\forall/\forall\formost.
\]
In effect, we asked Merlin to attach to his proof the offsets $d^{(1)}, \ldots, d^{(s)}$ that make sure that Arthur always accepts when $x \in L$. This means that there are no “false negatives” anymore. Also, since $\exists\forall/\forall\formost \sse \exists\forall/\forall\exists$ by weakining, this shows that $\MA \sse \Sigma_2\PTIME$.
Similarly, for $\AM$,
\[
\AM = \formost\exists/\formost\forall \stackrel{\text{squint}}\sse (\forall\formost)\exists/(\formost\forall)\forall \stackrel{\text{weaken}}\sse \forall\exists\exists/\formost\forall\forall \stackrel{\text{combine}}= \forall\exists/\formost\forall.
\]
This time, we used the “$\coclass$” version of squinting, and Arthur is only drawing the offsets, while Merlin tries to find a random string such that the verifier accepts on all the offsets. When $x \in L$, Merlin is always able to succeed, so there are no “false negatives”. Also, since $\forall\exists/\formost\forall \sse \forall\exists/\exists\forall$ by weakning, this implies $\AM \sse \Pi_2\PTIME$.
$\MA \sse \AM$
On a surface level, $\MA$ and $\AM$ seem incomparable: they’re the same class with the order of quantifiers flipped, just like $\Sigma_2\PTIME$ and $\Pi_2\PTIME$. But it turns out that $\MA \sse \AM$: it’s always better for Arthur to go first.
- For $x\in L$, this is true because $\exists \formost$ logically implies $\formost \exists$: the only thing that changes between $\MA$ and $\AM$ is that Merlin now gets to see Arthur’s coin flips before sending his message, so that can only help him make Arthur accept.
- For $x\not\in L$, on the other hand (and for the same reasons), $\forall \formost$ does not directly imply $\formost \forall$: even if no message of Merlin can fool Arthur on average when Merlin goes first, once the order is flipped, Merlin might be able to do better by adaptively choosing which message to send based on Arthur’s message. But if the probability Arthur is fooled is small compared to the number of possible messages for Merlin, then most of the time Arthur cannot be fooled by any message.
In math, this gives
\[\MA = \exists\formost/\forall\formost \stackrel{\text{specialize}}\sse \formost\exists/\forall\formost \stackrel{\text{union bound}}= \formost\exists/\formost\forall = \AM.\]
Overall, we can summarize what we know about these classes in this diagram (classes that are generally believed to be equal are shaded together):
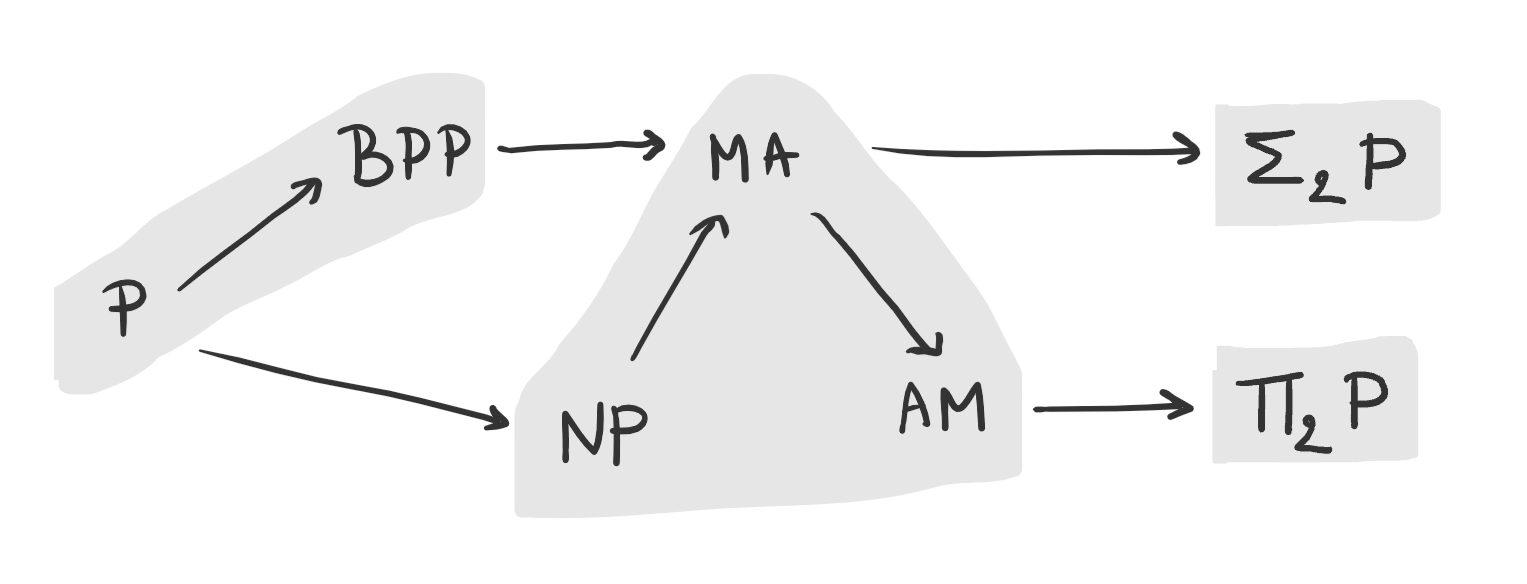
Constant-round protocols are all in $\AM$
One might think that by adding more rounds of interaction between Arthur and Merlin, we can keep extending the class of languages. But this is not the case! The reason is the intuition that we got from the previous section: it’s always better for Arthur to go before Merlin, so we can transform the protocol so that Arthur sends all of his messages first, then Merlin sends all of his messages.
For example, consider the class $\mathsf{AMA}$ where Arthur goes first and last. Informally, we know that $\MA \sse \AM$, so it’s tempting to write $\mathsf{AMA} \sse \mathsf{AAM} = \mathsf{AM}$. This is not quite how math works but it’s fundamentally the right idea. More formally, we can write $\mathsf{AMA}$ as $\formost\exists\formost/\formost\forall\formost$, so we can pull the same trick where we flip $\exists\formost/\forall\formost$ into $\formost\exists/\formost\forall$, then combine quantifiers.
\[\mathsf{AMA} = \formost\exists\formost/\formost\forall\formost \stackrel{\text{specialize}}\sse \formost\formost\exists/\formost\forall\formost \stackrel{\text{union bound}}= \formost\formost\exists/\formost\formost\forall \stackrel{\text{combine}}= \formost\exists/\formost\forall = \AM.\]
What if $\NP \sse \BPP$?
In complexity we often think of $\PTIME$ as the definition of “efficient computation”. But what would happen if we used $\BPP$ instead?
One important result is to show that if $\NP$ was “easy” (i.e. $\PTIME = \NP$), then dramatic things would happen (i.e. the polynomial hierarchy would collapse). What would happen if $\NP \sse \BPP$?
If we had an $\NP$ oracle within $\BPP$, then in particular, we could use it to solve $\Sigma_2\PTIME$ within $\MA$: use Merlin for the first quantifier, then let Arthur use the $\NP$ oracle to handle the second quantifier:
\[\Sigma_2\PTIME = \exists\forall/\forall\exists \stackrel{\NP \sse \BPP}\sse \exists\formost/\forall\formost = \MA.\]
But we know $\MA \sse \AM \sse \Pi_2\PTIME$. So we would have $\Sigma_2\PTIME \sse \Pi_2\PTIME$ and the polynomial hierarchy would collapse to the second level.
Appendix: I lied a bit
This appendix is boring, please don’t read it.
I claimed earlier that we can always replace $\forall\formost$ by $\formost\forall$, and $\formost/\formost$ by $\formost\forall/\forall\formost$. Well, it’s a bit more complicated. The thing is, these tricks required some change to the computation that follows:
- For the “union bound” in $\forall\formost \to \formost\forall$ to work, we need to boost the probability of success. This involves repeating the computation several times in parallel and taking the majority of the answers.
- For the “squinting” trick in $\formost/\formost \to \formost\forall/\forall\formost$ we need to first boost the probability of succes then run this boosted computation at several offsets $d^{(1)}, \ldots, d^{(s)}$ and take the OR.
This means that we should be able to take majorities or ORs in the underlying computation model. For $\BPP$, this was no problem: once $x$ and $r$ are chosen, the remaining computation $V(x,r)$ is deterministic polynomial time, so repeating $\poly(n)$ times and computing the majority is no big deal. On the other hand, imagine we’re looking at $\AM = \formost\exists/\formost\forall$. Then the computation that follows the “for most” quantifier is an $\NP$-type computation. Can we compute the majority of some $\NP$ computations within $\NP$ itself? Given that we cannot even easily negate the result of an $\NP$ computation (unless $\NP = \coclass\NP$), this seems worrying.
However, it does turn out to be okay, and ultimately this comes down to the fact that you can push monotone operations like $\and$ and $\or$ inside quantifiers $\exists$ and $\forall$: for example <div>[(\exists y_1 : P(y_1)) \and (\exists y_2 : P(y_2)) \Leftrightarrow \exists y_1, y_2: P(y_1) \and P(y_2).]</div>
Concretely, for boosting probabilities, we get
- if $x \in L$, then $\formost r_1, \ldots, r_k : \Maj_i\p{\One[\exists y: V(x,r_i,y)) = 1]} = 1$;
- if $x \not\in L$, then $\formost r_1, \ldots, r_k : \Maj_i\p{\One[\forall y: V(x,r_i,y) = 0]} = 1$.
Which is equivalent to
- if $x \in L$, then $\formost r_1, \ldots, r_k, \exists y_1,\ldots, y_k: \Maj_i(V(x,r_i,y)) = 1$;
- if $x \not\in L$, then $\formost r_1, \ldots, r_k, \forall y_1, \ldots, y_k : \Maj_i(V(x,r_i,y)) = 0$.